This project belongs to the 'Knowledge Organization and Digital Methods in the Cultural Heritage Domain' course of University of Bologna, a.y. 2018/2019. Its aim is to create a Linked Open Data sample for describing data related to the event of the Protestant Reformation.
The Protestant Reformation is the religious separation movement from the Catholic Church in the 16th century. It represented, both from the historical and cultural point of view, a strong influence on the society of that time and thus gave origin to many artifacts – from paintings, to documents, to music – which testify its undeniable relevance. For this reason, we chose to deepen this event by analyzing it in all its possible manifestations.
E/R Model
In this section, we present our project through an E/R Model (i.e. Entity / Relationship model), a theoretical and conceptual way of showing data relationships.
Below, the E/R Model is shown as an abstract diagram for the visual representation of our relational database.
Click on the image to see it bigger.

Entities
In our E/R model, we chose to take into consideration five types of entities. Click on the following icons to discover which entities we chose for each category and the relative connections with the others.





Items

First item
"Disputatio pro declaratione
virtutis indulgentiarum"

Second item
"Septembertestament"

Third item
"Das Zeitalter der Reformation"

Fourth item
"Gli effetti della Riforma protestante"

Fifth item
"Bulla contra errores Martini Lutheri & sequacium"

Sixth item
"Institutio christianae religionis"

Seventh item
Memorial stone

Eighth item
"Ein feste Burg ist unser Gott"

Ninth item
"Broadsheet for the Centenary
of the Reformation"

Tenth item
"Verdammnis und Erlösung"

Eleventh item
Medal










Metadata alignment
In this step, we described the metadata standards used by the institutions in which our eleven items are held.
In particular "an alignment is a match between one or more elements in one schema to one or more elements in another schema"1.
1 Maria Violeta Bertolini et al., "Guidelines for use of ISBD as linked data". Final draft: August 2016. IFLA, 2016.
At first, we aligned our eleven items with their providers and the used standards. In the case of the presence of digital platforms that work as cultural heritage aggregators (Europeana collections, CulturaItalia, Google Arts & Culture, museum-digital), we have also provided the specific heritage institution in which the object is kept.
| Object type | Title | Provider | Metadata Standard |
|---|---|---|---|
| "Disputatio pro declaratione virtutis indulgentiarum" | Staatsbibliothek zu Berlin | EAC-CPF | |
| Book | "Septembertestament" | Wolfenbütteler Digitalen Bibliothek | TEI |
| “Das Zeitalter der Reformation” | Library of Congress | DC | |
| Book | “Gli effetti della Riforma protestante” | CulturaItalia (Biblioteca Nazionale Braidense) | PICO |
| Document | “Bulla contra errores Martini Lutheri & sequacium” | CulturaItalia | PICO |
| Monograph | “Institutio christianae religionis, Iohanne Caluuino authore” | CulturaItalia (Biblioteca Nazionale Centrale - Firenze) | PICO |
| Photograph | "Memorial stone to the 400th anniversary of the Reformation" | Europeana | EDM |
| Sound recording |
"Ein feste Burg ist unser Gott” | Europeana (Biblioteca Nazionale Centrale di Roma) | EDM |
| Broadsheet | "Broadsheet for the Centenary of the Reformation" | Google Arts & Culture (Staatliche Museen zu Berlin) | CIDOC-CRM |
| Painting | "Verdammnis und Erlösung" | Museum-digital (Das Schlossmuseum Gotha) | LIDO |
| Medal | Untitled | Europeana (Stadtgeschichtlichen Museums Leipzig) | EDM |
Secondly, we aligned the standards previously cited (EAC-CPF, PICO, TEI, LIDO, EDM, DC and CIDOC-CRM) matching their properties.
In particular, we divided the properties according to the three main categories/questions (WHO, WHAT, WHERE) in which our five entities (Person, Concept, Event, Artifact, Place) are divided.
Regarding the WHEN category, it has been inserted as a property (i.e. as an attribute, in the E/R model) under the category WHAT: this was done for the need to specify the date only of our entity Artifact.
Click on the image below to see the table.

Click here to download the PDF.
Theoretical model
The drawing up of our theoretical model is aimed at explaining how we use the existent ontologies and their properties in the description of the entities belonging to our five categories (EVENT, PERSON, CONCEPT, ARTIFACT, PLACE).
This has been done replying to four questions:
- WHO? - people: creators, influencers, predecessors, successors. How to describe them?
- WHERE? - places: original places, locations at a certain time period. Which information do we have to represent about them?
- WHEN? - dates: crucial life events, historical events. In which format do you need to express the notion of time?
- WHAT? - objects: concepts and items of cultural heritage. What are the main contents and properties of the objects?
Who
It was of utmost importance for us to point out a person as an entity, so that it could be related in different ways to all types of cultural objects we had selected. In particular, we have chosen to enrich knowledge about a person by including such important properties as Name, Gender, Citizenship, Education, Occupation and his and her Role in the event, as a representative of a religious movement.
In order to achieve our goal of describing people involved in our project in the most complete and profound way possible, we choose:
- FOAF Vocabulary Specification, which is a widely used ontology for describing persons and their relationships;
- Person Core Vocabulary, that provides a minimum set of classes and properties for describing a natural person as opposed to any role they may play in society or the relationships they have to other people, organizations and properties; we used this ontology especially for the reason that Person Core Vocabulary is an ontology meant specifically to describe historical people.
- Core Concepts Ontology, which is the generic BBC ontology for people, places, events, organizations, concepts.
- DBpedia, due to our approach based also on the need to present each individual from the perspective of a person’s crucial life events. While examining the ontologies, we decided to opt for it because it allowed us to add such properties as Date Of Birth and Date Of Death, but also unusual properties like Citizenship.
Moreover, the ‘person’ as a metadata element can be interpreted as in relationship with the other entities. In particular, for what regards the connection with the ARTIFACT entity, we took into consideration several ontologies:
- Dublin Core Metadata Initiative, for the properties that indicate the creator (painter, author), the publisher and the contributors of the items;
- OAD, the ontology for archival description, to depict the provider of the items kept in archives;
- RDA, to express the creator and the keeper of the bibliographical entries of libraries.
- CIDOC-CRM, a formal ontology intended to facilitate the integration, mediation and interchange of heterogeneous cultural heritage information. We used it to indicate the creator of museum items.
This ontology was ideal for our purpose because of its precision on the definition of the entities and the related predicates. For this reason, we used it also in the context of the other different entities: - CONCEPT: it has been used to express the main protagonists of the religious movements Lutheranism and Calvinism;
- EVENT: to depict the participants of the Protestant Reformation.
Where
In an event-centric approach, as the one we decided to use in our project, the representation and description of places is mandatory. In the context of the description of the entity PLACE, we used the most used ontologies in this field:
- GeoNames Ontology (GN), excellent in adding geospatial semantic information to the Word Wide Web because of its 11 million geonames toponyms that have an unique URL;
- Basic Geo (WGS84) Vocabulary, a basic xml vocabulary that provides the Semantic Web community only with a namespace for representing latitude and longitude;
- DBpedia, when the previous two lacked of certain properties (such as Country or Abstract as a brief description of the place).
Moreover, the reason why, in our case, the geographical aspect becomes important and meaningful is that a city (or more widely, a country) can be be linked to the other entities:
- ARTIFACT: in this category, the places are identified in the place of creation of the chosen item and in its current location. For this reasons, we used three different ontologies: Dublin Core Metadata Initiative in the duo 'dcterms:coverage' and 'dcterms:spatial', OAD (for archival items) and CIDOC-CRM (for museum items);
- EVENT: the Protestant Reformation, only entity in this class, took place in a city, but due to its great reach and extent, we chose to identify it with a nation (Germany) rather than a city. CIDOC-CRM, again, was the best option, because its perspective is supra-institutional and abstracted from any specific local context;
- PERSON: the locations connected with a certain life period of a person were handled by Person Core Vocabulary, as already specified above.
When
While dealing with dates, we represented them in the format suggested by w3Consortium - Date and Time Formats (i.e. DD/MM/YYYY). Hence, our data present date either as YYYY or, when possible, DD/MM/YYYY.
What
In order to describe our artifacts in a deeper way, we adopted those vocabularies that provided us with necessary properties for an accurate and consistent identification of a resource. As far as possible, we have tried to make use of the most popular and widely accepted ontologies that already exist in the field of cultural heritage.
For a better understanding of the objects related to people, places, and concepts, we distinguished our artifacts according to their institutions (museum, archive, library) and labeled them as books, manuscripts, paintings, broadsheets and so on. Our need for detailed metadata description has led us to combine various ontologies.
Without forgetting what institution objects belong to, we employed the following ontologies:
- Archives - Dublin Core Metadata Initiative, OAD, EAC-CPF;
- Libraries - Dublin Core Metadata Initiative, RDA;
- Museums - Dublin Core Metadata Initiative, CIDOC-CRM.
For our LOD project, the event (the Protestant Reformation) is the real core and it is connected to concepts, people and artifacts. We have chosen CIDOC-CRM in order to describe our core event by the ‘class’ E5_Event, that already exists in the ontology. The great variety of CIDOC-CRM predicates has led us to be as very specific as we wanted. For example, it was possible for us to show the relationship between the Protestant Reformation and Martin Luther by using a very specific property (i.e. E5_Event > P11_had_participant > E39_Actor) or between it and the Ninety-Five Theses (i.e. E5_Event > P12_occured in_the_presence_of > E77_Persisent_Item).
From the very beginning, we were looking for an extensible ontology for concepts and relationships that was currently used in cultural heritage domain. Almost all the needs of the project regarding concepts was satisfied by making use of CIDOC-CRM. Furthermore, we could represent the relationship of each concept with the other entities (person, event) through this same ontology.
We further made use of Dublin Core Metadata Initiative and DBpedia in order to link the concept to other referenced documents and resources, such as the Wikipedia page describing it, so to enrich our Linked Data space with external URIs.
Conceptual model
In this section, we present the formal/conceptual model created in order to transform the previous theoretical model in something computable. A conceptual model, in fact, is a model that defines, for our five categories of entities (Person, Place, Concept, Artifact, Event), the way in which we will write the properties according to the ontologies chosen and described in the theoretical model, and then their objects (in form of the triple subject-property-object).
Click on the following icons to open the related sections of the conceptual model.
Clicking here or on the image below, you will find a diagram in an Entity-Relation Model style that depicts the conceptual mapping of all our 19 entities: the 11 items, the 3 persons, the 2 places and the 2 concepts and the 1 event. We have chosen to create it in order to give an immediate view of the connections of this project.
The linkage has been made with 'natural language' predicates that we created by taking inspiration from the ontologies that we have used.

Mapping

Data description
On the based of the realized conceptual model, we described all our 19 entities:
- 11 items:
- "Disputatio pro declaratione virtutis indulgentiarum";
- "Septembertestament";
- "Das Zeitalter der Reformation";
- "Gli effetti della Riforma protestante";
- "Bulla contra errores Martini Lutheri & sequacium";
- "Institutio christianae religionis";
- "Gedenkstein zum 400. Jahrestag der Reformation";
- "Ein feste Burg ist unser Gott";
- "Broadsheet for the Centenary of the Reformation";
- "Verdammnis und Erlösung";
- "Medal on the introduction of the Reformation in Saxony in 1839";
- 3 persons (Martin Luther, John Calvin, Pope Leo X);
- 2 concepts (Lutheranism, Calvinism);
- 2 places (Wittenberg, Nuremberg);
- 1 central event entity, the Protestant Reformation.
All tables can be clicked and contain links to anchors placed in other places of the same page or of other tables, to enrich the exploration of the deep interconnection of our entities.
RDF & data connection
Abstract
In this section we create URIs (Uniform Resource Identifiers: strings of characters that unambiguously identify a resource) for the most important entities belonging to our project, for a total number of 9 different URIs. All of them can be found in our GitHub repository.
Thus, we described our chosen entities through RDF (Resource Description Framework), a language for representing information about resources in the World Wide Web. In fact, RDF is based on the idea of identifying things using Web identifiers (URIs) and then connecting them to simple properties and values, in order to create triples of statements, each composed of:
- a subject: the Resource, that is anything that can have a URI;
- a predicate: the Property;
- an object: the Property value.
Since RDF documents are written in XML, we described our 9 entities with the RDF/XML language, which is the XML language specially used by RDF, equipped with its XML namespace declarations ("xmlns").
Moreover, it is possible to use several alternate concrete syntax for RDF, as defined in the "RDF Concepts and Abstract Syntax W3C Recommendation" [RDF11-CONCEPTS]. For this serialization, we decided to explore and use three different syntaxes:
- RDF/TURTLE serialization syntax. This serialization is divided in two parts:
- The first one contains the @prefix keywords, i.e. the namespace declarations: they are the association of a prefix used in the document with a URI, linked to the official documentation of the used ontology;
- The second one is made of triples, that firstly identify the subject, always a URI, and secondly all the relative properties and values (that could be URIs or literals).
- RDF/JSON (JavaScript Object Notation), that serializes a set of RDF triples as a series of nested data structures;
- N-TRIPLES, a line-based, plain text format for for parsing RDF/XML;
In the meantime, especially through our RDF/XML and TURTLE/XML serialization, we connected our data to other related items and resources on the World Wide Web. In particular, we linked the same authorities using the property "owl:sameAs" for what regards the names (people, places, concepts). That property is part of the Web Ontology Language (OWL), a Semantic Web language designed to represent rich and complex knowledge about things, groups of things, and relations between them.
Who
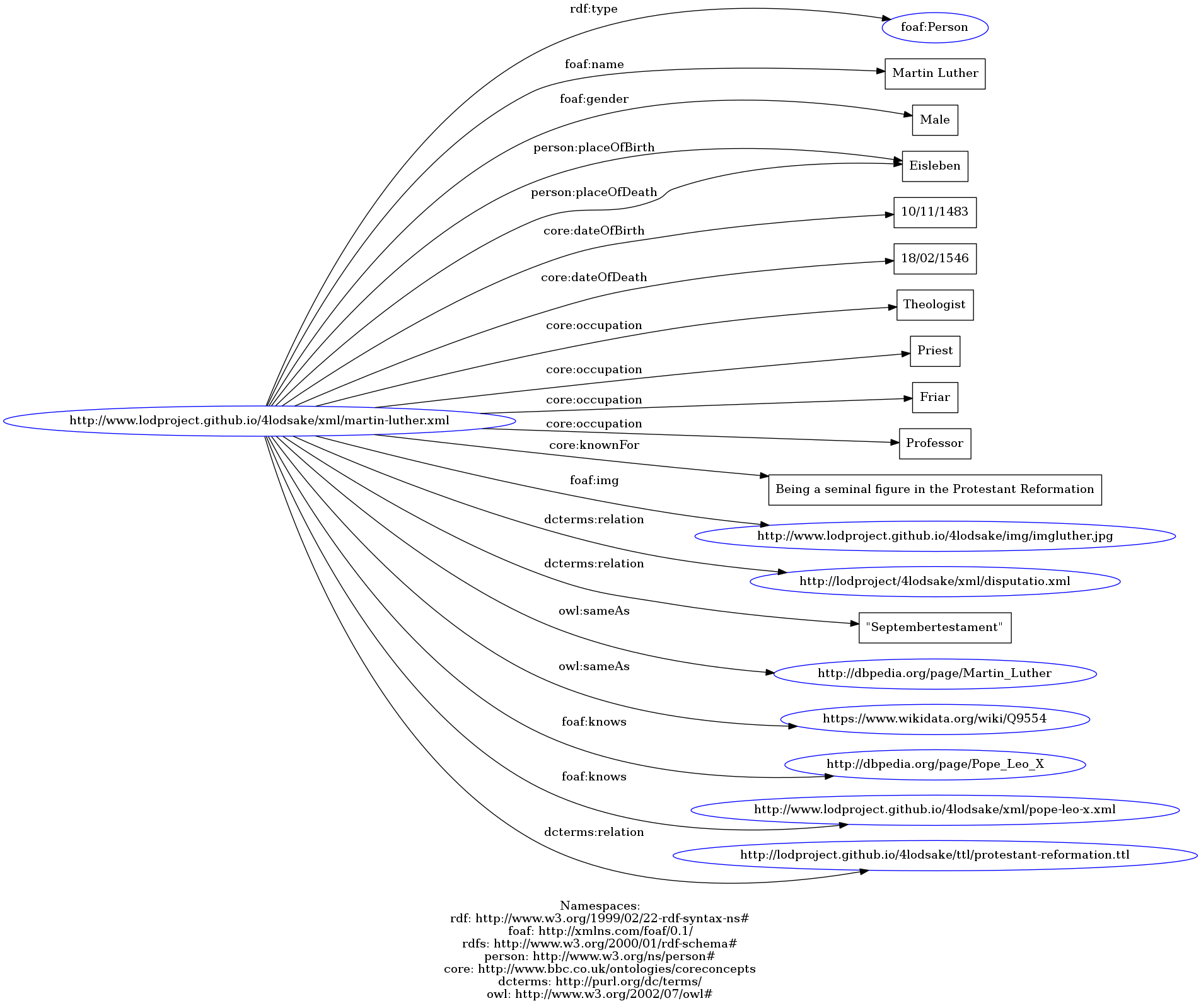
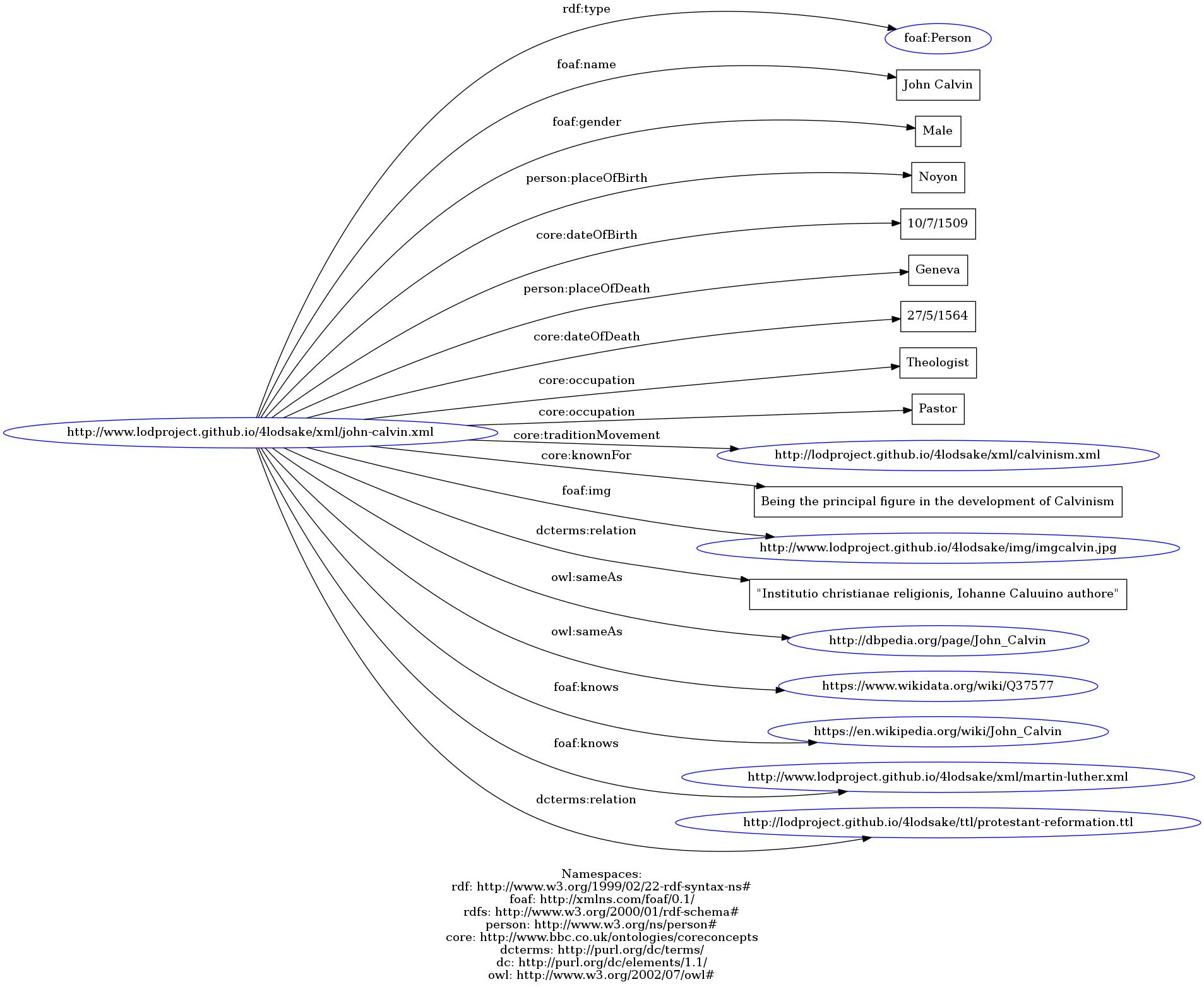
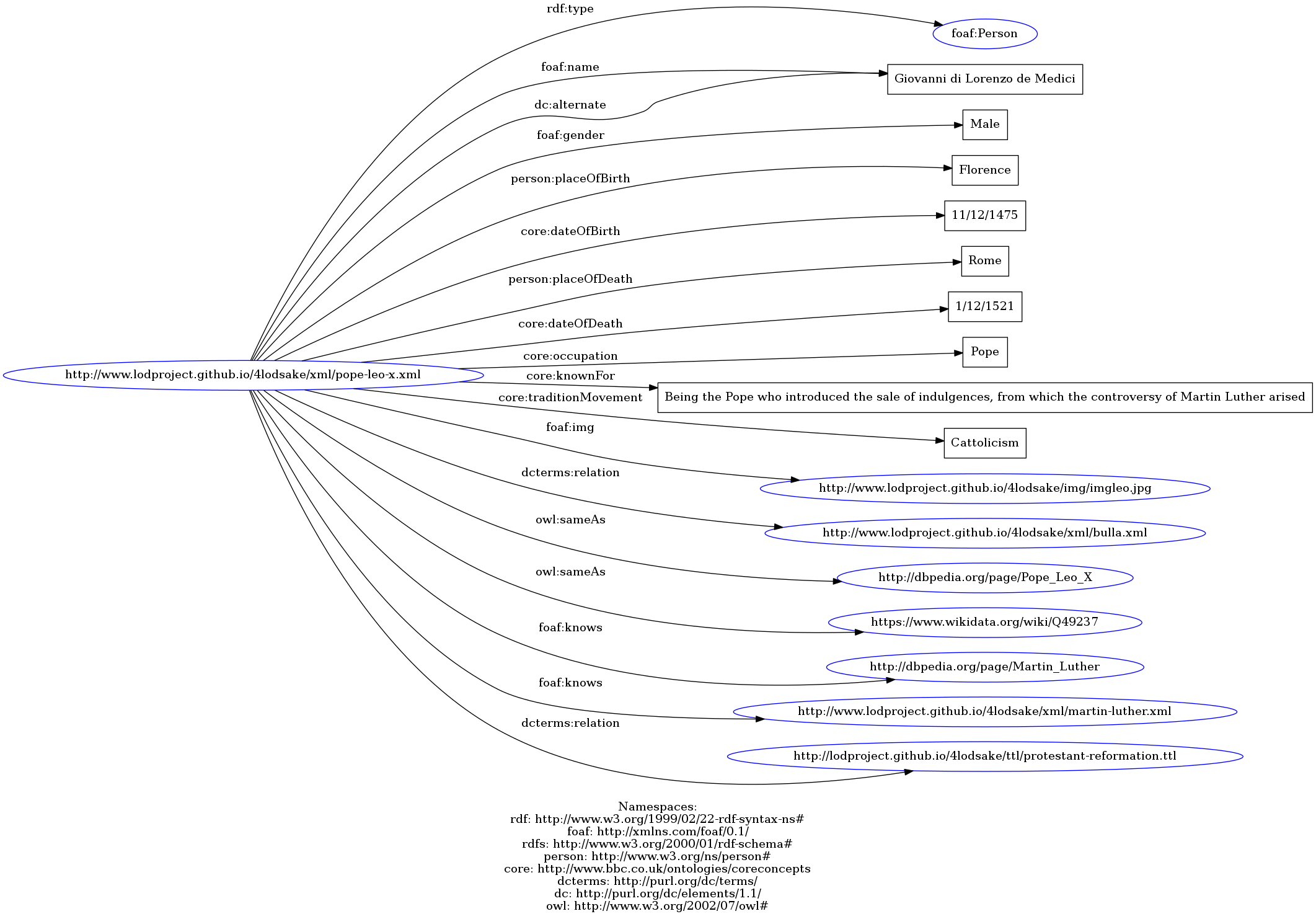
For the entity Person we have created URIs for all the protagonists of our project. By clicking on the links below, you can also see the connections with other resources.
What
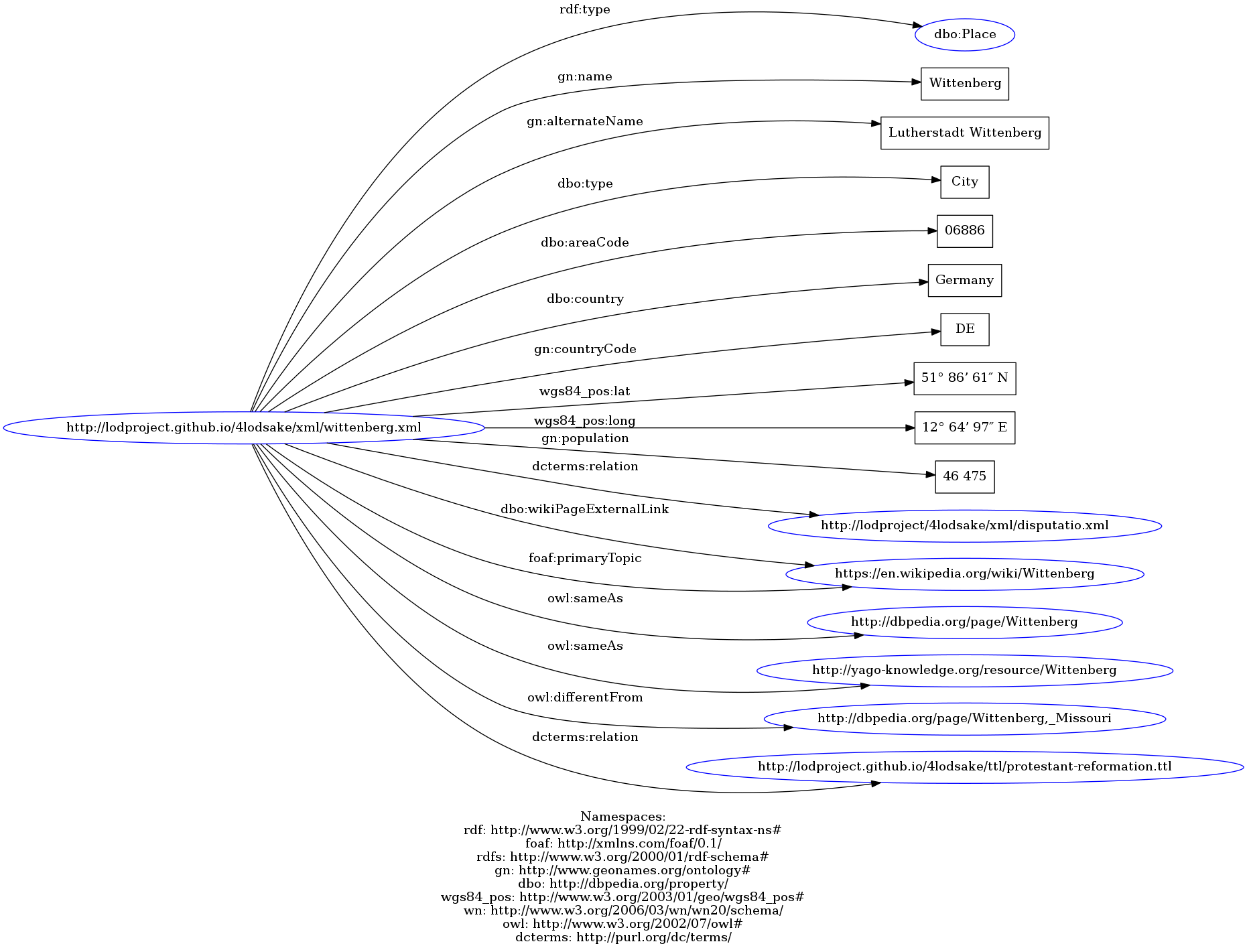
For the entity Artifact we have created URIs and RDF framework for:
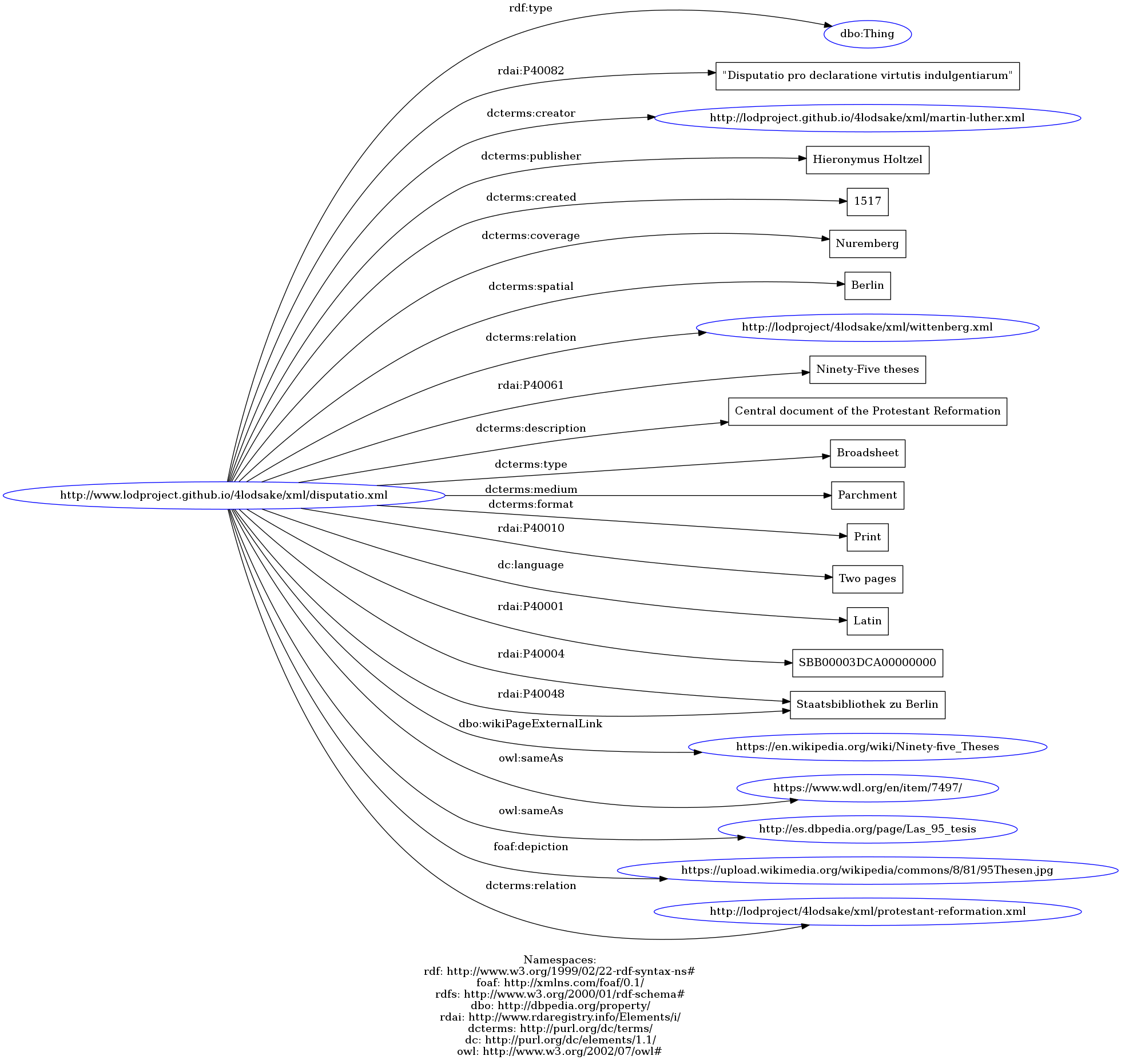
- "Disputatio pro declaratione virtutis indulgentiarum". See the XML file, the TURTLE file, the N-Triples file or the graph representation;
- "Bulla contra errores Martini Lutheri & sequacium". See the XML file, the TURTLE file or the graph representation.
For the Event category, we analyzed our only event:
- Protestant Reformation. See the XML file, the TURTLE file, the N-Triples file or the graph representation.
Here, we present the concepts underlying our artifacts and connected to our event:













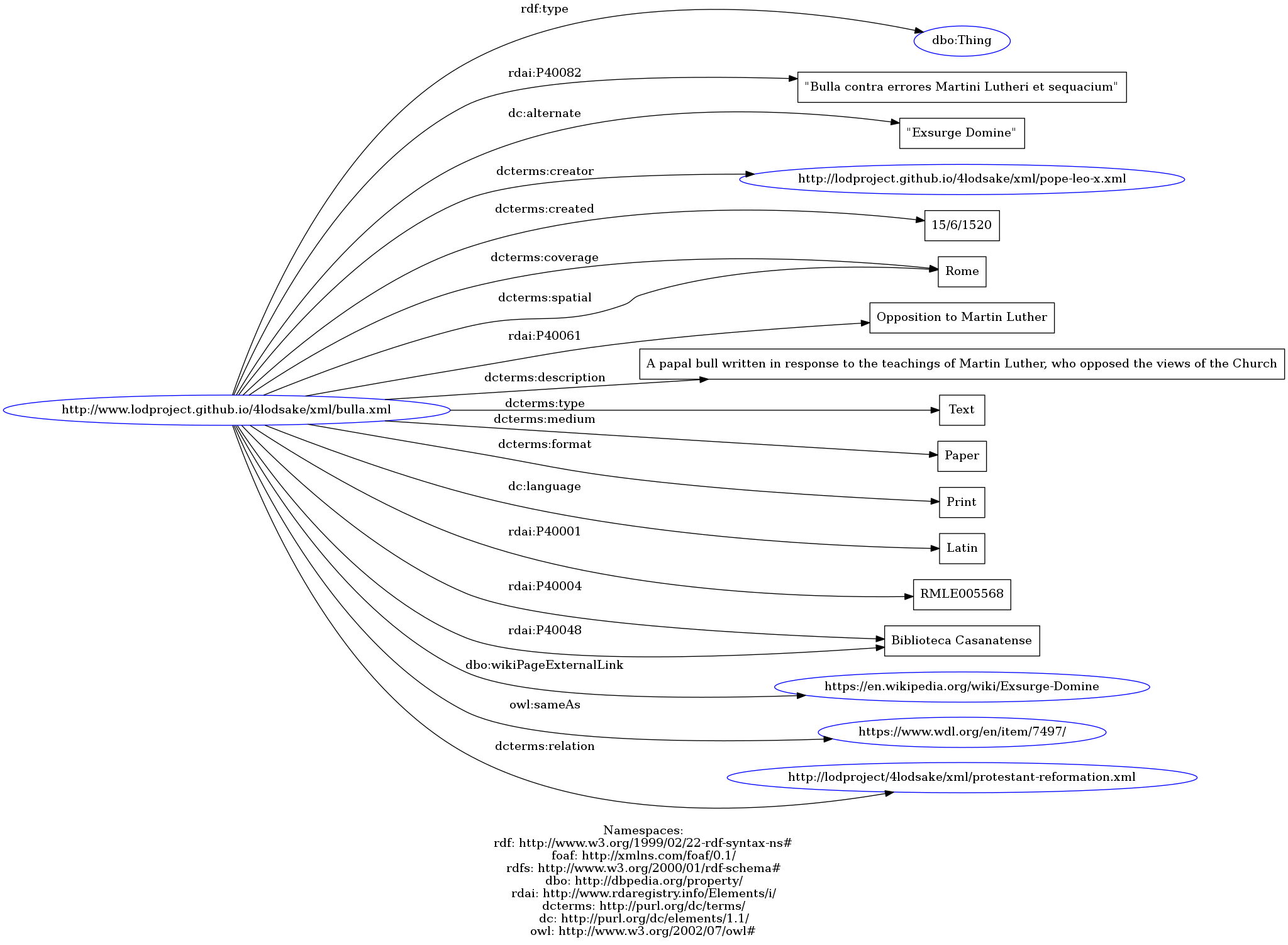



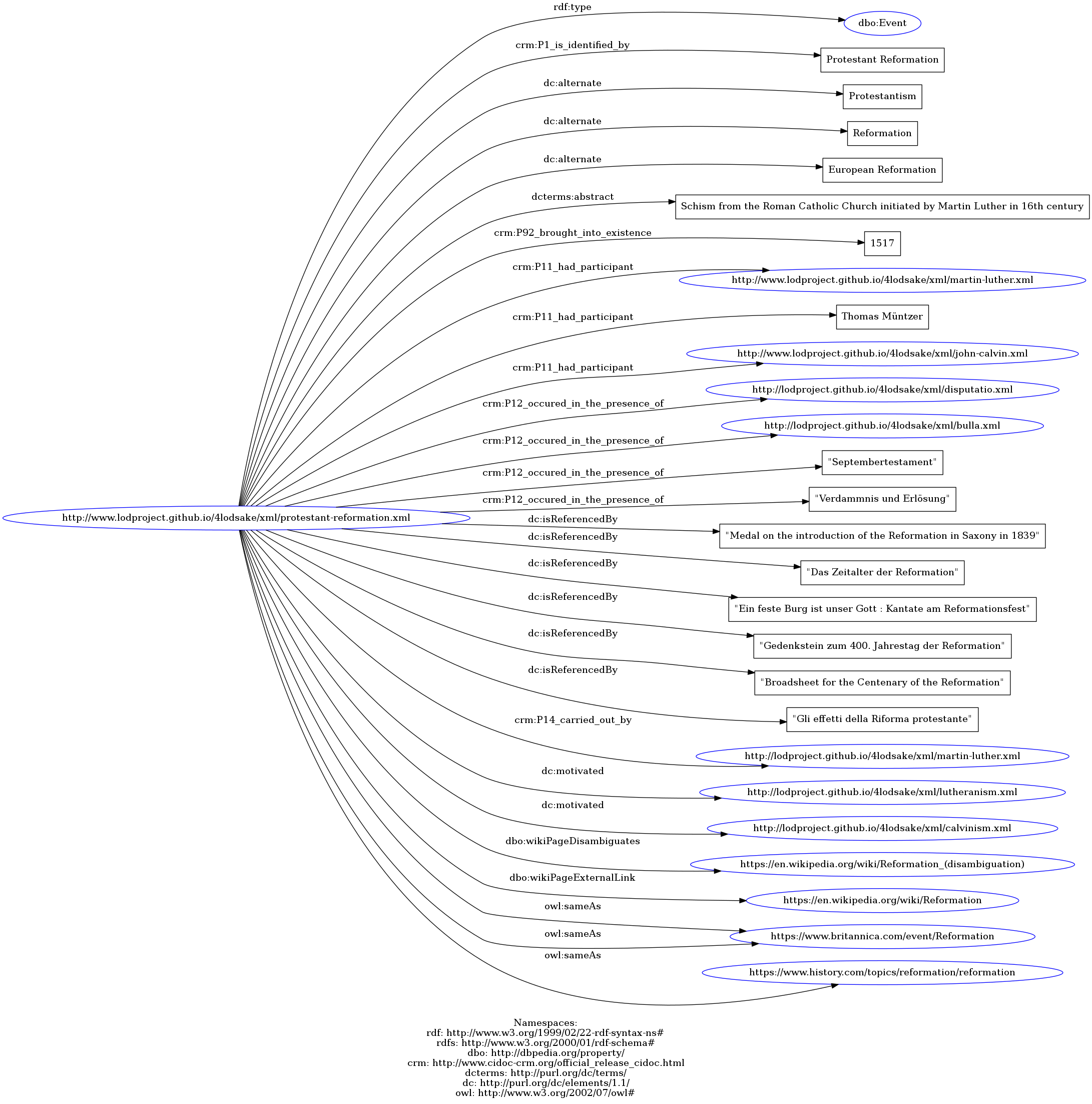


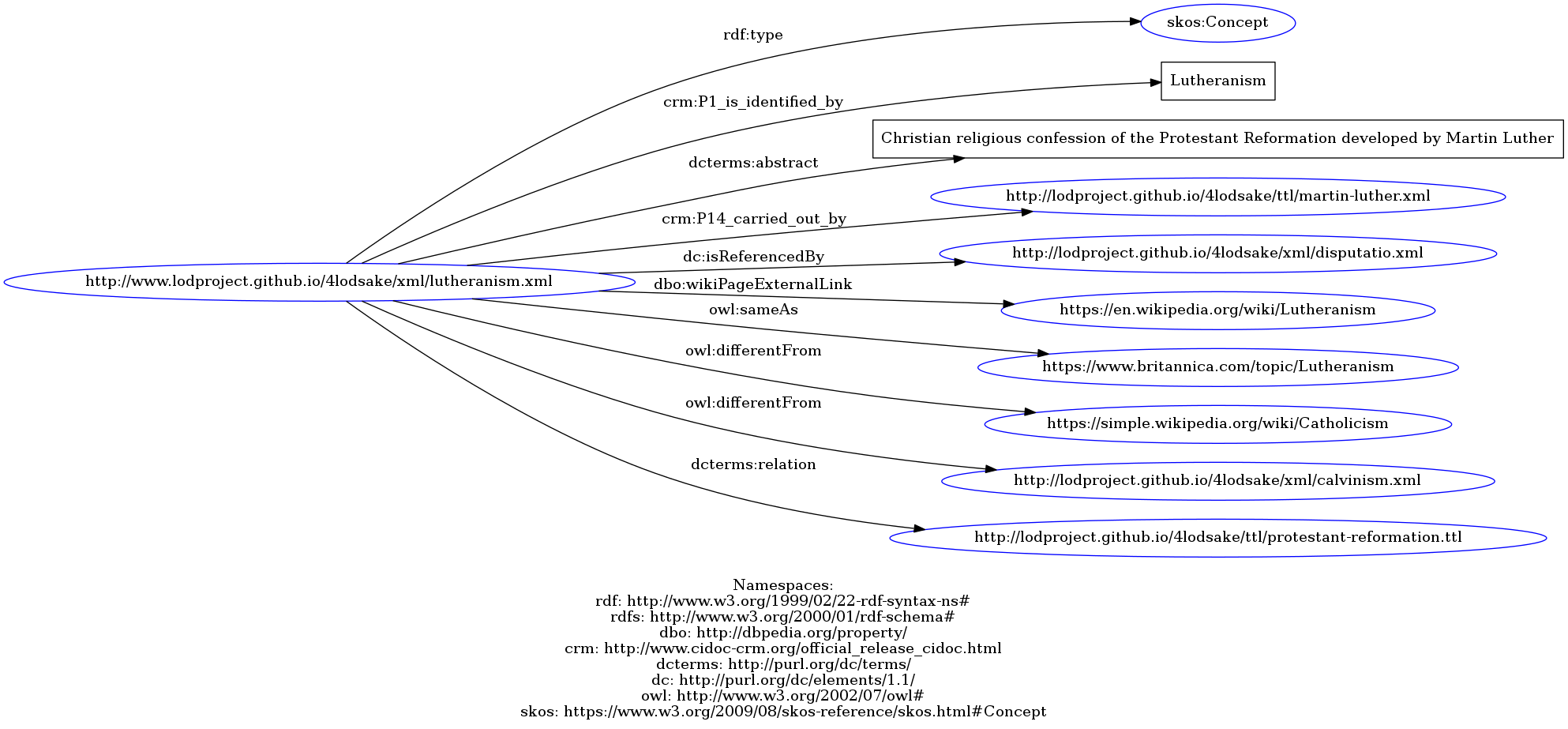


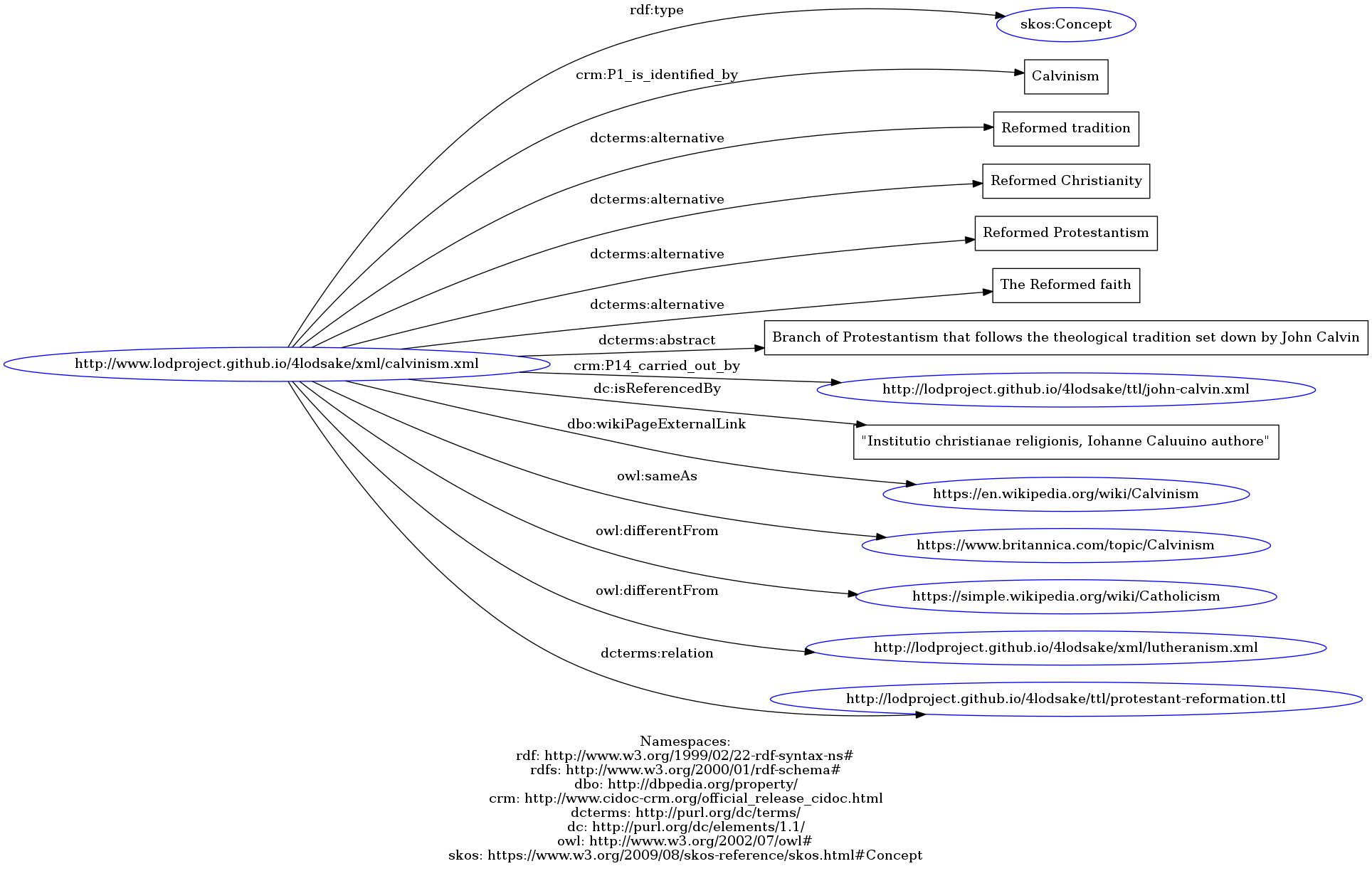


- Copyright and License -
- The MIT License (MIT).
- Copyright © 2013-2019 Blackrock Digital LLC.
- Simay Güzel
- Chantal Lengua
- Vittoria Moccia
- Lisa Siurina
All copyrights and related rights on the images remain with their original owners.